使用 Scrapy 和 Playwright 无限滚动抓取页面
使用 scrapy 抓取网站时,您很快就会遇到各种需要发挥创意或与要抓取的页面进行交互的场景。其中一种场景是当您需要抓取无限滚动页面时。当您向下滚动页面时,这种类型的网站页面会加载更多内容,就像社交媒体源一样。
抓取这些类型的页面的方法肯定不止一种。我最近解决这个问题的一种方法是继续滚动,直到页面长度停止增加(即滚动到底部)。这篇文章将逐步介绍这个过程。
这篇文章假设您已经设置并运行了一个 scrapy 项目,并且有一个可以修改和运行的 spider。
此集成使用 scrapy-playwright 插件将 playwright for python 与 scrapy 集成。 playwright 是一个无头浏览器自动化库,用于与网页交互并提取数据。
我一直在使用uv进行python包的安装和管理。
然后,我直接使用 uv 的虚拟环境:
uv venv source .venv/bin/activate
使用以下命令将 scrapy-playwright 插件和 playwright 安装到您的虚拟环境中:
uv pip install scrapy-playwright
安装您想要与 playwright 一起使用的浏览器。例如,要安装 chromium,您可以运行以下命令:
playwright install chromium
如果需要,您还可以安装其他浏览器,例如 firefox。
注意:以下 scrapy 代码和 playwright 集成仅使用 chromium 进行了测试。
更新settings.py文件或spider中的custom_settings属性以包含download_handlers和playwright_launch_options设置。
# settings.py
twisted_reactor = "twisted.internet.asyncioreactor.asyncioselectorreactor"
download_handlers = {
"http": "scrapy_playwright.handler.scrapyplaywrightdownloadhandler",
"https": "scrapy_playwright.handler.scrapyplaywrightdownloadhandler",
}
playwright_launch_options = {
# optional for cors issues
"args": [
"--disable-web-security",
"--disable-features=isolateorigins,site-per-process",
],
# optional for debugging
"headless": false,
},
对于 playwright_launch_options,您可以将 headless 选项设置为 false,以打开浏览器实例并观察进程运行。这有利于调试和构建初始抓取器。
我传递了额外的参数来禁用网络安全并隔离来源。当您抓取存在 cors 问题的网站时,这非常有用。
例如,可能会出现由于 cors 导致所需的 javascript 资源未加载或未发出网络请求的情况。如果某些页面操作(例如单击按钮)未按预期工作但其他一切都正常,您可以通过检查浏览器控制台是否有错误来更快地隔离此问题。
"playwright_launch_options": {
"args": [
"--disable-web-security",
"--disable-features=isolateorigins,site-per-process",
],
"headless": false,
}
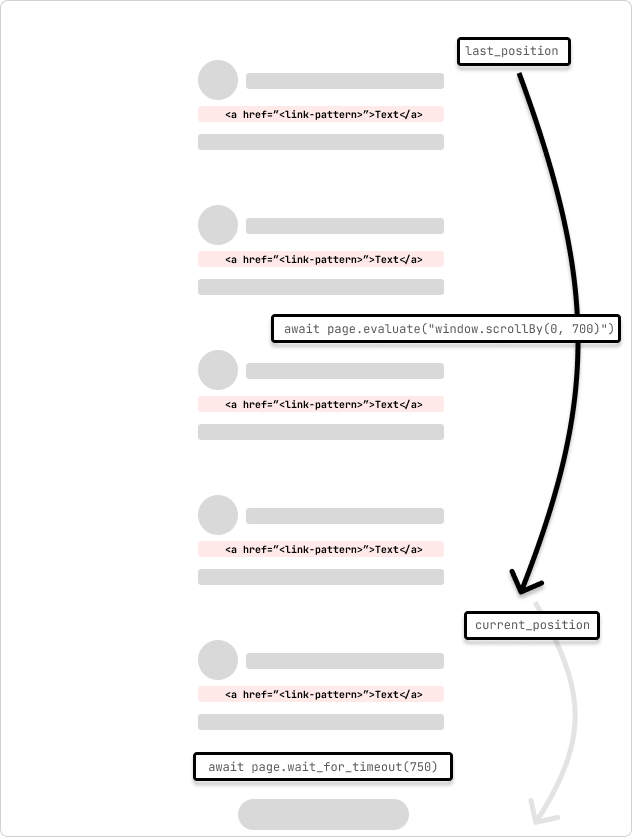
这是一个爬行无限滚动页面的蜘蛛的示例。蜘蛛将页面滚动 700 像素,并等待 750 毫秒以完成请求。蜘蛛将继续滚动,直到到达页面底部,滚动位置在循环过程中不会改变。
我正在使用 custom_settings 修改蜘蛛本身的设置,以将设置保留在一处。您还可以将这些设置添加到settings.py文件中。
# /<project>/spiders/infinite_scroll.py
import scrapy
from scrapy.spiders import crawlspider
from scrapy.selector import selector
class infinitepagespider(crawlspider):
"""
spider to crawl an infinite scroll page
"""
name = "infinite_scroll"
allowed_domains = ["<allowed_domain>"]
start_urls = ["<start_url>"]
custom_settings = {
"twisted_reactor": "twisted.internet.asyncioreactor.asyncioselectorreactor",
"download_handlers": {
"https": "scrapy_playwright.handler.scrapyplaywrightdownloadhandler",
"http": "scrapy_playwright.handler.scrapyplaywrightdownloadhandler",
},
"playwright_launch_options": {
"args": [
"--disable-web-security",
"--disable-features=isolateorigins,site-per-process",
],
"headless": false,
},
"log_level": "info",
}
def start_requests(self):
yield scrapy.request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=true,
playwright_include_page=true,
),
callback=self.parse,
)
async def parse(
self,
response,
):
page = response.meta["playwright_page"]
page.set_default_timeout(10000)
await page.wait_for_timeout(5000)
try:
last_position = await page.evaluate("window.scrolly")
while true:
# scroll by 700 while not at the bottom
await page.evaluate("window.scrollby(0, 700)")
await page.wait_for_timeout(750) # wait for 750ms for the request to complete
current_position = await page.evaluate("window.scrolly")
if current_position == last_position:
print("reached the bottom of the page.")
break
last_position = current_position
except exception as error:
print(f"error: {error}")
pass
print("getting content")
content = await page.content()
print("parsing content")
selector = selector(text=content)
print("extracting links")
links = selector.xpath("//a[contains(@href, '/<link-pattern>/')]//@href").getall()
print(f"found {len(links)} links...")
print("yielding links")
for link in links:
yield {"link": link}
</link-pattern></start_url></allowed_domain></project>我了解到的一件事是,没有两个页面或站点是相同的,因此您可能需要调整滚动量和等待时间以考虑页面以及网络往返中的任何延迟以完成请求。您可以通过检查滚动位置和完成请求所需的时间以编程方式动态调整此值。
在页面加载时,我等待资源加载和页面渲染的时间稍长一些。 playwright 页面被传递到response.meta 对象中的解析回调方法。这用于与页面交互并滚动页面。这是在 scrapy.request 参数中使用 playwright=true 和 playwright_include_page=true 选项指定的。
def start_requests(self):
yield scrapy.request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=true,
playwright_include_page=true,
),
callback=self.parse,
)
此蜘蛛将使用 page.evaluate 和scrollby() javascript 方法将页面滚动 700 像素,然后等待 750 毫秒以完成请求。然后,将 playwright 页面内容复制到 scrapy 选择器,并从页面中提取链接。然后,这些链接将被传送到 scrapy 管道以继续处理。
对于页面请求开始加载重复内容的情况,可以添加一个检查,看看内容是否已经加载完毕,然后跳出循环。或者,如果您知道滚动加载的数量,则可以添加一个计数器,以便在一定数量的滚动加上/减去缓冲区后跳出循环。
页面也可能有一个可以滚动到的元素(即“加载更多”),该元素将触发下一组内容的加载。您可以使用 page.evaluate 方法滚动到该元素,然后单击它以加载下一组内容。
...
try:
while True:
button = page.locator('//button[contains(., "Load more")]')
await button.wait_for()
if not button:
print("No 'Load more' button found.")
break
is_disabled = await button.is_disabled()
if is_disabled:
print("Button is disabled.")
break
await button.scroll_into_view_if_needed()
await button.click()
await page.wait_for_timeout(750)
except Exception as error:
print(f"Error: {error}")
pass
...
当您知道页面有一个将加载下一组内容的按钮时,此方法非常有用。您还可以使用此方法单击其他元素,这将触发下一组内容的加载。如果按钮或元素在页面上不可见,则scroll_into_view_if_needed 方法会将按钮或元素滚动到视图中。这是其中一种场景,您需要使用 headless=false 仔细检查页面操作,以查看在运行完整爬网之前是否单击了按钮以及是否按预期加载了内容。
注意:如上所述,确认页面资源(.js)正确加载并且正在发出网络请求,以便按钮(或元素)已安装并可点击。
网络爬行是一个具体情况具体分析的情况,您将需要调整代码以适应您要抓取的页面。上面的代码是让您使用 scrapy 和 playwright 爬行无限滚动页面的起点。
希望这可以帮助您解除封锁! ?
订阅通过电子邮件获取我的最新内容-> newsletter
以上就是使用 Scrapy 和 Playwright 无限滚动抓取页面的详细内容,更多请关注php中文网其它相关文章!
 《无所畏惧》温莉的结局是什么
时间:2023-11-25
《无所畏惧》温莉的结局是什么
时间:2023-11-25
 《无所畏惧》刘铭的结局是什么
时间:2023-11-25
《无所畏惧》刘铭的结局是什么
时间:2023-11-25
 《无所畏惧》罗英子和陈硕最后在一起了吗
时间:2023-11-25
《无所畏惧》罗英子和陈硕最后在一起了吗
时间:2023-11-25
 《宁安如梦》 姜雪宁是如何设计让薛姝去和亲
时间:2023-11-25
《宁安如梦》 姜雪宁是如何设计让薛姝去和亲
时间:2023-11-25
 《宁安如梦》薛姝为了不和亲做了什么
时间:2023-11-25
《宁安如梦》薛姝为了不和亲做了什么
时间:2023-11-25
 《宁安如梦》为什么姜雪蕙只能当侧妃
时间:2023-11-25
《宁安如梦》为什么姜雪蕙只能当侧妃
时间:2023-11-25













